您現在的位置是:首頁 > 藝術
AI虛擬人,漸行漸近
ai如何確定六邊形的邊長

機器人與小觀眾現場互動。(科大訊飛供圖)
想足不出戶遊覽祖國大好河山?與表情豐富、情感細膩的虛擬導遊來一場對話吧,無須穿戴裝置就能“打破”空間界限,“說走就走”帶你“瞬移”到旅遊景點,目及之處皆是美景、遠觀近瞧隨心所欲,開啟一場身臨其境的沉浸式“雲旅遊”。
這個AI能力“硬核”的虛擬導遊就是AI虛擬人,它整合“訊飛超腦2030計劃”的多模感知、多維表達、深度理解等多項前沿技術,使真人和虛擬人可以非常自然地“穿越”不同場景對話,給人機互動帶來全新的沉浸式體驗。
11月18日,2022科大訊飛全球1024開發者節在合肥正式啟幕,在釋出會上,科大訊飛AI研究院副院長高建清以“AI新紀元,訊飛超腦2030”為主題,解密“訊飛超腦2030計劃”階段性技術突破。他表示,隨著AI虛擬人的誕生,一大波“預演未來”的創新應用將走入百姓生活,讓AI惠及每個人。
超腦2030計劃賦能AI虛擬人更懂知識
“麵包在低溫下會馬上發黴嗎”?AI虛擬人要回答這一問題,就必須理解“低溫變質慢”等常識,在引入海量知識的基礎上,用預訓練模型進行知識重要性排序,並融合知識與問題進行推理,這樣才能與人暢聊“麵包變質的二三事”。
然而,讓AI虛擬人擁有這種知識推理卻並非易事,必須要“超腦”賦能才行。2022年伊始,科大訊飛正式釋出“訊飛超腦2030計劃”,核心是透過AI技術持續的核心源頭技術創新和系統性創新,讓機器遠不止具備“你問我答”的基礎智慧,還擁有更強的互動和運動能力。只有讓人工智慧“懂知識、善學習、能進化”,才能讓機器人走進每一個家庭,以解決未來社會重大剛需命題。
“實現‘訊飛超腦2030計劃’,要突破人工智慧共性基礎演算法,攻克多模感知、多維表達、認知智慧、運動智慧等核心技術,也要研究軟硬一體的機器人關鍵技術。此外,要探索虛擬人互動、機器人等方面的示範應用。”高建清說。
作為“訊飛超腦2030計劃”的階段性成果,今年,訊飛已打造多款專業虛擬人,分別用於客服、助理、招聘、財務、法務等工作,為金融、電信、媒體等行業提供專業虛擬人解決方案,為“數字經濟”服務。
“目前科大訊飛虛擬人播報支援包括中文、英語、日語、韓語、西班牙語等多種語言及四川話、粵語、藏語、維吾爾語等多種方言。”高建清介紹,科大訊飛強大的AI技術支撐,使虛擬人不僅可以滿足各場景的播報需要,也可以出色地完成主持、客服、陪伴、直播等互動工作,提供導航導覽、業務知識、生活服務、資訊查詢等互動式AI服務。
創新“互動”技術對話“滔滔不絕”
想向AI虛擬人瞭解《獨行月球》這部電影的內容?沒問題!今年,科大訊飛在互動系統的認知關鍵技術取得突破性進展,依託科大訊飛建設的認知智慧國家重點實驗室相關團隊在認知智慧技術突破方面奪得3項國際冠軍——在常識推理挑戰賽中重新整理機器常識推理水平世界紀錄,在科學常識推理挑戰賽中以準確率94。2%的絕對優勢奪冠,在常識推理挑戰賽中以多模型準確率93。48%、單模型準確率92。07%奪冠,後兩項比賽成績更是超越人類平均水平。
隨著核心源頭技術創新和系統性創新的持續突破,AI虛擬人擁有更加“智慧”的語義理解和對話生成能力。“好的人機互動系統,在開放式場景下要具備深度理解能力,並能瞭解互動物件從而發起主動對話。”高建清說,圍繞認知智慧技術,訊飛實現了基於語義圖網路的開放場景語義理解、基於事理圖譜的對話管理以及基於知識學習的可控對話生成。其中,面向開放世界的基於圖表示的深度語義理解體系,透過增加關係預測模組形成了資訊豐富的語義表示圖,並將要素和關係進行具體化,從而可以更精準地理解使用者意圖、更準確回答使用者問題,解決了AI對開放問題無能為力的痛點。目前,訊飛定義了1517個意圖、近2000個事件。“透過這個框架的提出,我們在深度語義理解技術上又邁進了一大步。”高建清說。

機器人與小觀眾現場互動。(科大訊飛供圖)
“唇形+語音”多模感知“喚醒”互動新模式
環境太吵、人聲太多,語音互動怎麼辦?在“訊飛超腦2030計劃”中,科大訊飛用“唇形+語音”的多模態語音增強技術,喚醒智慧語音互動新模式。
“機器想更自然地與人類進行互動,需要透過聽覺、視覺、語義以及各種感測器的組合去獲取更多的有用資訊,AI感知方式必然要從單模態發展到多模態,逐步擬人化。”高建清表示。
繼“語音識別在多人討論場景下效果做到70%”“多點噪聲干擾場景做到了可用”之後,今年,科大訊飛挑戰商場、醫院、地鐵等複雜場景,提出全新的多模態語音增強與識別框架。結合影片資訊輸入,新技術可以利用人臉、唇形、語音等多模態資訊的互補,將主說話人的乾淨人聲從嘈雜背景環境中分離出來,顯著提升開放場景的識別效果。
一個典型的場景是,當你在嘈雜的環境中通話,旁邊其他人也在說話,搭載多模感知技術的應用系統能夠只“聽”到你的聲音,不受旁邊嘈雜音干擾,從而順利完成溝通。“這一方案,從使用者主觀理解度層面有了極大改善,是真正站在使用者體驗角度最佳化系統的一種方法。”高建清表示,這個演算法主要解決“語音識別準確率高,但使用者體驗不好”的現實問題。
多情感多風格語音合成虛擬人有溫度有個性
如何讓機器的聲音媲美人類?這是智慧語音合成技術領域需求量大、技術門檻高的難題。高建清分享了科大訊飛在語音合成技術領域的新突破——多風格多情感合成系統SMART-TTS,語音合成從簡單的資訊播報“變身”具備喜怒哀樂情感的語音助手。
據介紹,SMART-TTS系統可提供“高興、抱歉、撒嬌、嚴肅、悲傷、困惑、害怕、鼓勵、生氣、安慰、寵溺”等11種情感,每種情感有20檔強弱度不同的調節能力;也能提供聲音的創造能力,如停頓、重音、語速等,使用者可以根據自己喜好調節,真正實現了合成系統媲美具備個性化特點的真人表達能力。
當你漫步林蔭路,它可以用字正腔圓的“播音腔”為你讀新聞;當你結束一天工作準備入睡,它可以輕聲細語為你讀散文;當你驅車去公司上班,它可以用你最喜歡的歌手聲音告訴你走哪條路不堵車;當你和家人一起觀看紀錄片,它可以為紀錄片不同人物配音。人機互動表達自然、情感飽滿。
在聲音和虛擬形象生成技術方面,科大訊飛實現語義可控的聲音、形象生成,語義驅動的情感、動作表達。比如,輸入“一頭長髮”,系統智慧生成溫柔大方的女性形象,聲音端莊又不失甜美;輸入“英俊瀟灑”,生成商務範兒的男生形象,聲音略帶磁性。據瞭解,訊飛開放平臺將開放500個虛擬合成的聲音。
此外,科大訊飛還實現了語音語義驅動的動作合成,透過對語音節奏、韻律體會和語義理解,虛擬人可以隨時、流暢地切換動作,擁有更加自然的肢體語言。
記者 汪永安 見習記者 鹿嘉惠
【來源:中安線上】
宣告:轉載此文是出於傳遞更多資訊之目的。若有來源標註錯誤或侵犯了您的合法權益,請作者持權屬證明與本網聯絡,我們將及時更正、刪除,謝謝。 郵箱地址:newmedia@xxcb。cn
推薦文章
- 中國裝備志——83式152毫米自行榴彈炮
 使用一門改進過的152毫米83式榴彈炮,炮塔配置三桶式液壓平衡機,火炮俯仰角為-5~65°,炮口採用雙室制退器,同時配有抽菸裝置但並未安裝空調過濾這類的三防系統,並採用剛性連線的半自動裝彈機裝彈,最大射速5發/分鐘,彈藥基數30發,車體內放...
使用一門改進過的152毫米83式榴彈炮,炮塔配置三桶式液壓平衡機,火炮俯仰角為-5~65°,炮口採用雙室制退器,同時配有抽菸裝置但並未安裝空調過濾這類的三防系統,並採用剛性連線的半自動裝彈機裝彈,最大射速5發/分鐘,彈藥基數30發,車體內放... - 伊能靜兒子換女友?相擁貼臉摟腰滿臉享受,網友:精神好像不正常
 很多人都對他穿女裝的行為發出質疑,但他表示,自己不過才20歲,還沒有定型,應該嘗試很多的東西...
很多人都對他穿女裝的行為發出質疑,但他表示,自己不過才20歲,還沒有定型,應該嘗試很多的東西... - 龍湖智創生活:蓄力靜候時機
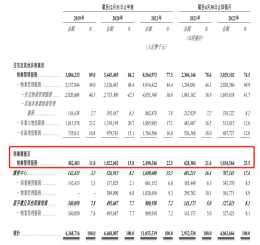 高質量規模增長在“物管”和“商管”之間端平了水,龍湖智創生活業務涵蓋住宅及其他非商業物業管理服務,和商業運營管理服務...
高質量規模增長在“物管”和“商管”之間端平了水,龍湖智創生活業務涵蓋住宅及其他非商業物業管理服務,和商業運營管理服務...